
There's a moment in any foray into new technological territory when you realize you may have embarked on a Sisyphean task. Staring at the multitude of options available to take on the project, you research your options, read the documentation, and start to work—only to find that actually just defining the problem may be more work than finding the actual solution.
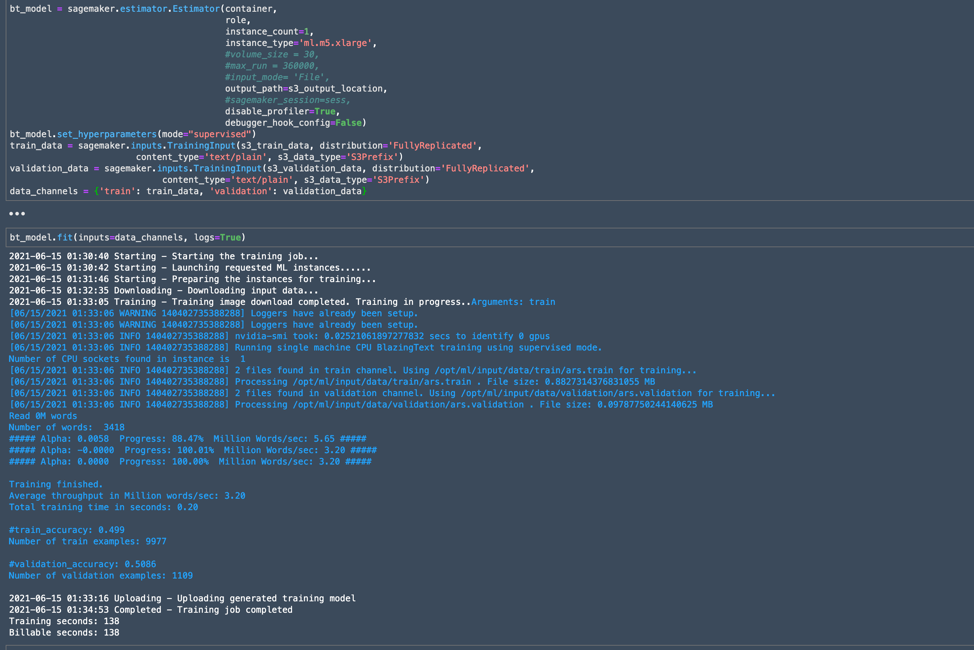
Reader, this is where I found myself two weeks into this adventure in machine learning. I familiarized myself with the data, the tools, and the known approaches to problems with this kind of data, and I tried several approaches to solving what on the surface seemed to be a simple machine-learning problem: based on past performance, could we predict whether any given Ars headline will be a winner in an A/B test?
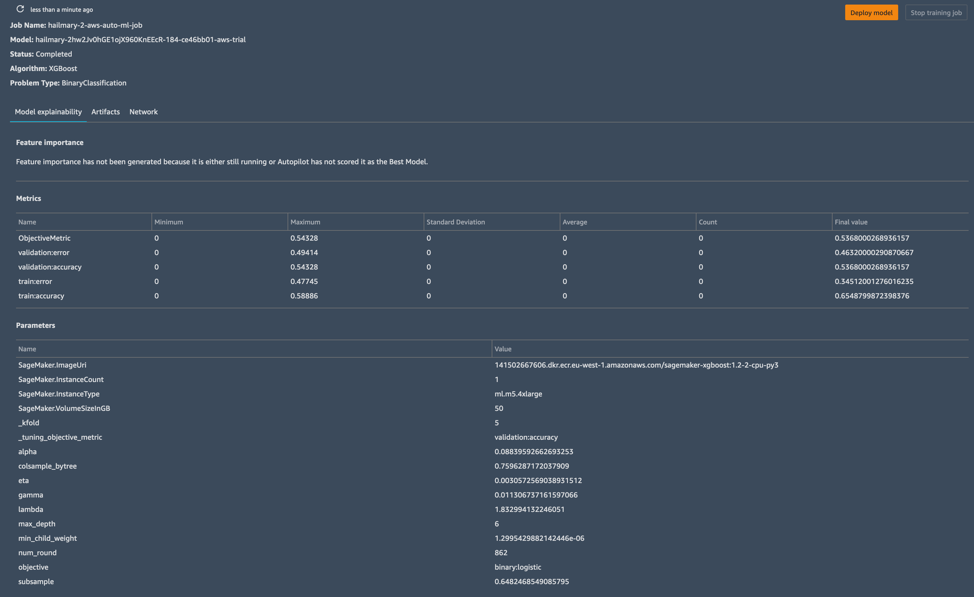
Things have not been going particularly well. In fact, as I finished this piece, my most recent attempt showed that our algorithm was about as accurate as a coin flip.
But at least that was a start. And in the process of getting there, I learned a great deal about the data cleansing and pre-processing that goes into any machine-learning project.
Prepping the battlefield
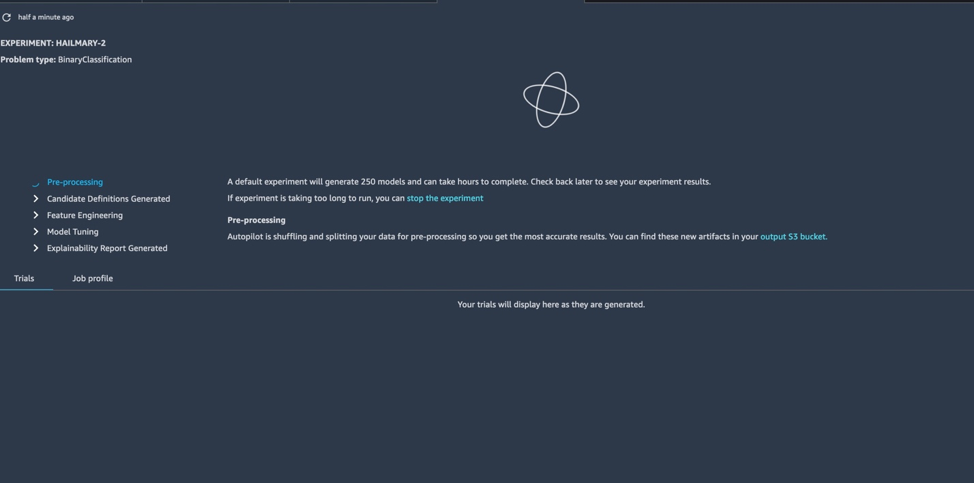
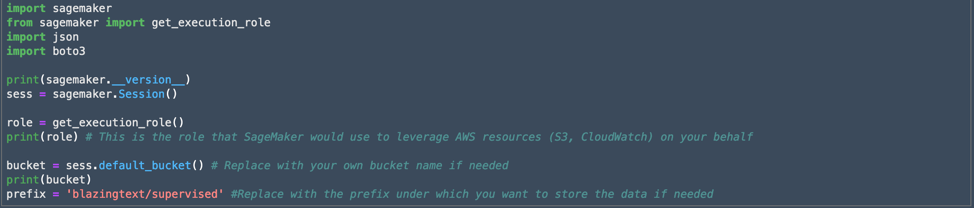
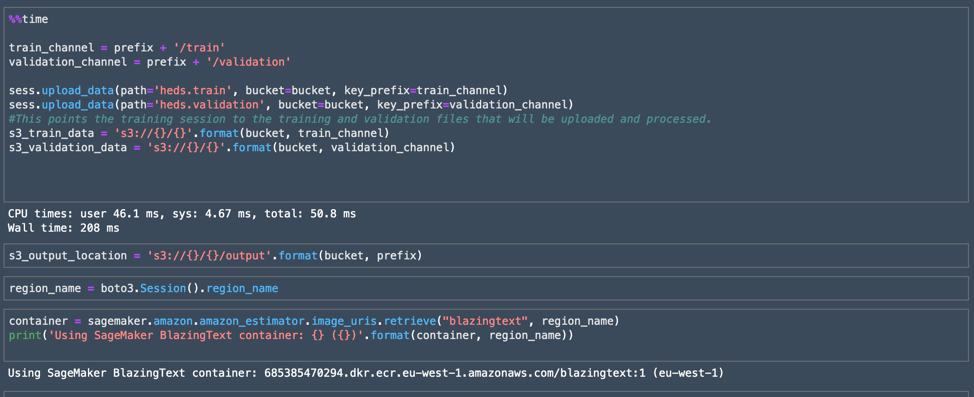
Our data source is a log of the outcomes from 5,500-plus headline A/B tests over the past five years—that's about as long as Ars has been doing this sort of headline shootout for each story that gets posted. Since we have labels for all this data (that is, we know whether it won or lost its A/B test), this would appear to be a supervised learning problem. All I really needed to do to prepare the data was to make sure it was properly formatted for the model I chose to use to create our algorithm.

 Loading comments...
Loading comments...
