

 Tweet
Tweet
 Share
Share
はじめに
初めまして、下記の記事にて紹介がありました
インフラエンジニアの榎戸です。
場数を踏んできたのかは分かりませんが 笑
23歳エンジニア歴は2年と浅めです。
まだまだ未熟なエンジニアですが
今回はPrometheus + Grafana
について紹介させて頂きます。
内容については下記となります。
- Prometheus導入の経緯
-
Prometheus概要
-
Prometheusでの監視構成
-
次回お知らせ
それでは始めていきます。
Prometheus導入の経緯
まずPrometheusを導入した経緯について少しだけ触れたいと思います。
弊社では月間20億PVのマンガサービスやそれと並行して走っているマンガサービス、また動画配信サービスや、アプリゲームの配信なども行なっております。
これらのサービスが会社の成長と共に大きくなり、やがてユーザー数が増え始めました。
ユーザー数が増えるということは嬉しい事ですが
裏側では以下のような問題が発生しておりました。
- サーバーコストの増加
- パフォーマンスのボトルネック箇所の特定がしにくい
- ログ監視ができていなかったのでエラーが起きた時に問題の特定ができない
こういった状況を改善するために、サーバー監視の体制を築こうと試みたようですが
- サーバー監視についてのノウハウを持ったエンジニアが少なかった
- サーバー監視体制構築の工数が取れなかった
上記の問題から、なかなかサーバー監視体制の構築に取り組めない状況にありました。
こういった状況を少しずつ改善していったのですが
中々サーバー監視の工数が取れず、そのままの状況が続いておりました。
そういった状況の中、前職でサーバの監視・運用を行っていた私が、9月に入社したことをきっかけに、いよいよサーバ監視を導入することとなりました。
最初は私の慣れ親しんだNagiosにてサーバの監視を導入したのですが・・・
今までサーバ監視の文化がなかった弊社に
NagiosのUIは受け入れてもらえませんでした・・・笑
(まだ残っているので少しだけ)
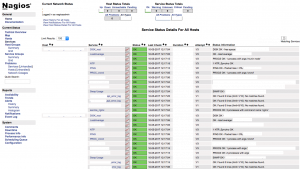
正直グラフをPluginで入れたとしても結構見辛いですしね・・・
あとはNagiosってアラートの管理とかが結構大変だったり
とか
オートスケールどうするの?
とか
何より世間ではMackerelが〜と騒がれている中
Nagiosっていうのもなー、という感覚がありました。
(ただ今のところlog監視についてはNagiosで行なっています。)
そこで折角の機会ですし
新しい監視ツールにチャレンジしてみようと思い
私の中で3つの候補を挙げました。
- Mackerel
-
Zabbix
-
Prometheus
また下記の判断基準で導入する監視ツールをPrometheusに決定致しました。
個人的主観や、扱っているサーバ等によっても変わってくるかと思いますので、実際に導入する際は参考程度にお願いします。
判断基準
- 理念や思想等
-
学習コスト
-
グラフ等の視覚的要素
-
監視を行う際の自由度
-
管理コスト
-
料金
Mackerel
- 理念や思想等
→今やサーバ管理・監視ツールはエンジニアだけが使うものではなく
色々な人が使うものであり、直感的にわかるようにするべき
→サーバの台数が増減するようなクラウドの環境でも
柔軟に対応できる監視ツールであるべき
はてなの方、こんな感じでよろしいでしょうか!
- 学習コスト
→多少発生しますが、Nagiosが使えるのでほとんど無い -
グラフ等の視覚的要素
→とても美しく、直感的に扱えるものとなっている -
監視を行う際の自由度
→かなり高いです
はてなさんの、実際に運用をしていたノウハウが詰まっています。
- 管理コスト
→管理コストも今までの監視ツールよりは低いと思います -
料金
→1台から50台までは1800円、以降は相談となるようです
Mackerelめちゃくちゃいいです。
正直採用をしたいところなのですが、料金がかかってしまうので、今の社内の状況的に導入は見送りにしました。
社内のインフラ環境などが綺麗になった段階や、情報が増えすぎて錯綜してしまうような状況になったら、導入しようと思っています。
Zabbix
- 理念や思想等
→オープソースの統合監視ツールとしての完成、これ一つで全て完結 -
学習コスト
→初期の学習コストが高め、一度作り込んでしまえば後はテンプレート化して楽になります -
グラフ等の視覚的要素
→綺麗に表示できますが、万人受けするかは分かりません(エンジニア向け) -
監視を行う際の自由度
→めちゃくちゃ高いです。基本的に思いつくものは大体できます
しかもしっかりとした書籍が多数出ていたり、日本で使用している企業が多い為情報がたくさんあります。
また完全OSSを謳っており、他の企業がお金を払って作ってもらった専用の機能なんかもしっかり公開されています。
本当に素晴らしい・・・
- 管理コスト
→高め、社内にZabbix masterみたいな人が生まれます笑 -
料金
→OSSの為無し
Zabbixはもの凄く自由度が高く、本当になんでも出来るツールなのですが
初期の学習コストと、作り込む為の作業工数がかかり過ぎてしまう点や、歴史が長く、結構昔からある監視ツールである為、現在主流のクラウドへ対応するまで、もう少し時間が掛かるかもしれないと判断したので見送りました。
Prometheus
- 理念や思想等
→アラート受けたくない。基本的にはクリティカルで人の対応が必要なものしか出さない
→クラウドなどサーバが増減する環境に最適化 -
学習コスト
→今のところめっちゃ高いです。日本語の記事等も少なく情報が掴みづらい状況です -
グラフ等の視覚的要素
→Grafanaと組み合わせなければなりませんが、めちゃくちゃ良いです -
監視を行う際の自由度
→サーバの情報を15秒に一回取得している(sarやdstatみたいな細かい情報)ので
後からでもその時の情報を取得できる。自由度は高め -
管理コスト
→情報がほとんど無いですが、高く無いと判断しています -
料金
→OSSの為無し
Prometheusは管理コストの低さとGrafanaでの描画の美しさ、カスタマイズのし易さに惹かれました。
ただβ版もリリースされたばかりで、日本語記事がほとんどなく、学習コストが高いことがかなりネックでした。
ですがアラートを受けたく無い、本当に人の対応がいるものだけをアラートとして出す、という設計思想にもの凄く共感しました。
またかなり細い情報まで取得して残しておいてくれるので、意図してアラートを組み込んでおかなくても、何かが起こった時に、Prometheusでほとんどの情報が取得出来るのが最高です。
上記の理由により
最近注目され始めたPrometheusでの監視を採用致しました。
全てのツールを完璧に使いこなした訳では無いので、主観が入ってしまっていますが
Prometheusの設計思想に惚れたから導入した、というのが率直な意見です。
Prometheus概要
そもそもPrometheusって何ですか?
そういう人も多いかと思いますので簡単に紹介したいと思います。
- Googleの出身者が、Googleで使用していた監視ツール「Borgmon」の影響を受けて作った
- AWS EC2や、kubernetesで管理されているDockerコンテナの監視を容易に行える
- Grafanaと組み合わせることで、美しい描画をしてくれる
- 不要なAlertを受けたくない、という思いから作られている
- 監視対象には、バイナリを一つ起動させておくだけ
- AWSのラベルで絞り込みができる
- 最近2系のβ版がリリースされ、僕的にはこれから注目されると信じているツール
去年にはサーバ1万台の監視を、Prometheusで行なったという記事も出ていました。
https://promcon.io/2016-berlin/talks/monitoring-dreamhack-the-worlds-largest-digital-festival/
またオートスケールしたインスタンスを自動で監視できたりと、AWSでの監視の設定がものすごく楽になります。
余談ですが描画ツールのGrafanaではCloudWatchの情報も取得できます。
つまりPrometheusと、CloudWatchのグラフを1つの画面で同時に表示できます!
これでサービスのサーバ群を、視覚的に確認することができるようになります。
こんな感じ(ClowdWatchから取得したELBとPrometheusから取得したCPU)
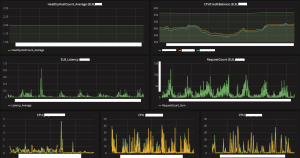
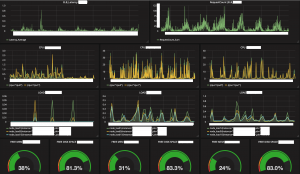
(Prometheusで取得した各サーバのリソース)
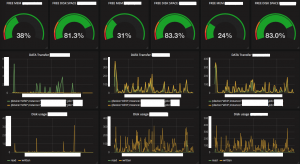
全体
Prometheusでの監視構成
弊社では下記のような形で監視を取得しております。

使用しているのは以下
– ClowdWatch
– Prometheus
– node_exporter
– alertmanager
– Grafana
Prometheusの機能を使い、EC2インスタンスをラベルで絞り込み監視を行なっています。
監視を行なっているのはPrometheus本体で、ここでアラートと判断された(閾値越え等)ものは、alertmanagerに渡されます。
alertmanagerでは、一度通知したアラートなのかどうかや
本当にこのアラートが必要なものかどうか、を判断してくれます。
本当に必要なアラートの場合は、alertmanagerに指定した通知先(mail,slack等)にアラートを出します。
また弊社では、ClowdWatchでも監視を行なっていますが、こちらの値をGrafanaで表示させることで
サーバのリソース(Prometheus)と、ClowdWatchでの値を合わせて確認できるようにしています。
これにより、サービス全体としてのリソースの使いかたや、サーバのスペックが最適かどうかなども、判断ができるようになりました。
次回お知らせ
次回はPrometheusのインストールと設定をAWS EC2を使って順番に説明していきます。
今回2.0.0-beta.5を導入したので、ほとんど日本語の記事がありませんでしたが
githubや作成者のブログを読んだりして構築しました。
公式のページにない情報などもいくつかありますので
どこのページを参照したのか等も合わせて記載していきたいと思いますのでぜひご覧ください。
また私自身も完璧にPrometheusを使いこなせている訳ではありませんので
次回記事では限定的でありますが、下記を紹介させて頂こうかと思っております。
- PrometheusでのAWS EC2インスタンスの絞り込み(localIPでの監視からpublicIPへの監視へ変換)
- Prometheus、alertmanager、node_exporterのinit-script
- alertmanagerでの通知先の設定(サービス単位での通知の振り分け)
- Grafanaを使った描画
また間違っている場所等御座いましたら
技術力向上の為ご連絡頂ければ幸いで御座います。
最後までご覧頂きありがとう御座いました。
※10月24日続編Vol2を記載しました。
こちらも宜しくお願い致します。