Google Search Console: Wie man Crawling und Indexierung steuern kann
Mit der Google Search Console kann man Einfluss auf den Googlebot und den Google-Index nehmen. Es gibt viele unterschiedliche Funktionen, die mal mehr, mal weniger hilfreich sind.
Der Google-Index ist sicherlich in Bezug auf SEO in Deutschland das wichtigste Ziel. Wer dort nicht optimal vertreten ist, kann von der reichweitenstärksten Suchmaschine nicht profitieren.
Gerade die Google Search Console bietet dabei viele Funktionen, um Einblicke in den Crawler und den Index zu bekommen – und darauf natürlich auch Einfluss auszuüben. Dieser Artikel bietet einen Überblick über die unterschiedlichen Funktionen und zeigt auch auf, wo die Grenzen der jeweiligen Tools liegen.
Crawling-Geschwindigkeit
Eine Möglichkeit, das Crawling zu beeinflussen, findet sich in den „Website-Einstellungen“. Dort kann man die maximale Crawling-Frequenz beschränken (siehe Abbildung 1). Das wird man allerdings nur dann tun, wenn die Website durch allzu viele Seitenabrufe der unterschiedlichen Google-Crawler beeinträchtigt wird.
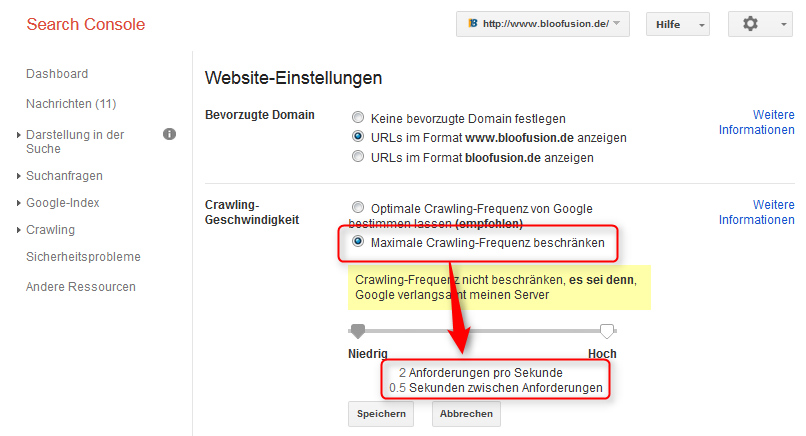
Abbildung 1: In Ausnahmefällen kann man die Crawling-Geschwindigkeit beschränken.
In der Regel wird man diese Einstellungsmöglichkeit also nicht nutzen und sich darauf verlassen, dass Google seinen Crawler nicht zu oft vorbeischickt. Wenn Google die Website beeinträchtigt, sollte das eher Motivation sein, über die Performance der eigenen Website nachzudenken und z. B. einen Cache zu implementieren.
Indexierungsstatus
Unter dem Punkt „Indexierungsstatus“ findet man eine Übersicht der indexierten Seiten. In dem Chart (siehe Abbildung 2) kann man im Zeitverlauf (ein Jahr) sehen, wie sich der Index verändert hat. Die Aussagekraft ist leider recht gering, da man zwar sehen kann, wie viele Seiten indexiert und für Suchmaschinen gesperrt sind. Welche Seiten konkret sich aber im Index befinden, kann man über die Google Search Console leider nicht einsehen.
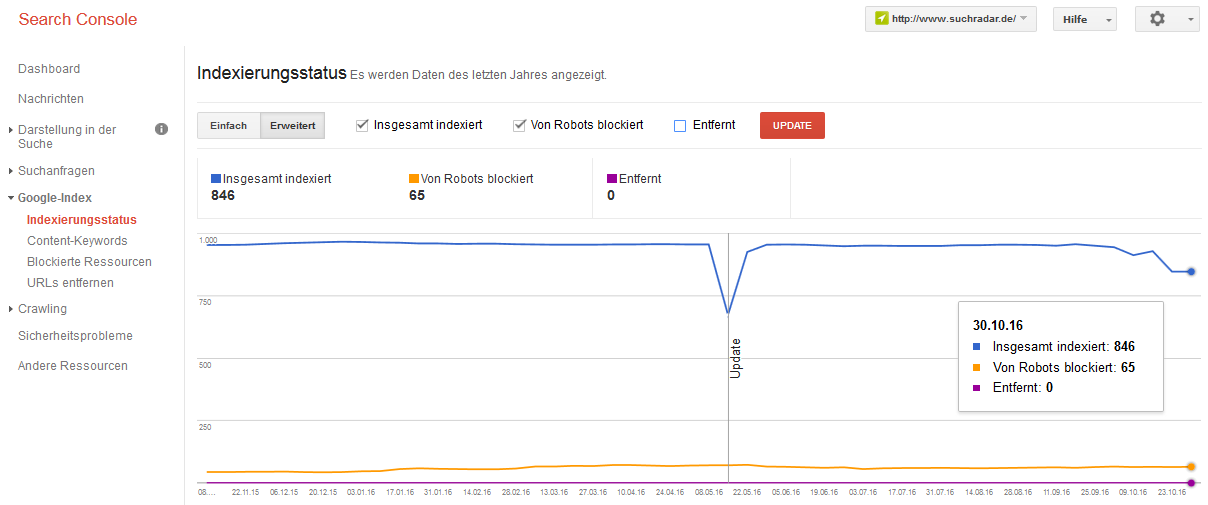
Abbildung 2: Die Anzahl der indexierten Seiten im Überblick – mehr bietet die Funktion „Indexierungsstatus“ leider nicht.
Man sollte also schon auf sprunghafte Veränderungen achten. Wenn es auf einmal einen Sprung nach oben gibt, könnte das darauf hindeuten, dass Google etwas indexiert, das vorher nicht verfügbar war. Dabei kann es sich natürlich um relevante Inhalte handeln – aber genauso gut auch um tausende irrelevante Seiten (z. B. Login-Seiten, Druckversionen …). Es kann aber auch einen Sprung nach unten geben, weil man z. B. versehentlich Inhalte für Suchmaschinen gesperrt hat.
In beiden Fällen hilft aber die Google Search Console leider nicht bei der weiteren Diagnose, da man nicht sehen kann, welche Seiten ursächlich für die Änderungen sind. Man ist hier also auf weitere Tools angewiesen. Eine Möglichkeit, um ein Anwachsen der indexierten Seiten zu erfassen, ist die Nutzung vom Screaming Frog Log Analyzer. Dort kann man die Log-Dateien des Web-Servers analysieren lassen, um so zu sehen, welche Seiten Google heruntergeladen hat. Wenn man diese dann über das Tool z. B. mit der XML-Sitemap abgleicht, kann man prüfen, welche Seiten, die nicht in der Sitemap sind, geladen werden. Das ist allerdings ein recht aufwendiger Vorgang, der aber auch nur in Ausnahmefällen nötig ist.
Seiten ausblenden
Manchmal gibt es auch Fälle, in denen Seiten, die sich im Index befinden, schnell wieder aus diesem entfernt werden müssen. Das ist z. B. dann notwendig, wenn einige Seiten rechtliche Probleme verursachen und zur Vermeidung von Strafen nicht mehr in den Suchergebnissen erscheinen sollten.
Auch hierzu bietet die Google Search Console Hilfe an. Über den Punkt „URLs entfernen“ (siehe Abbildung 3) kann man konkrete Seiten aus den Suchergebnissen ausblenden und/oder aus dem Cache entfernen. In der Regel wird man natürlich beides gleichzeitig machen, damit es auch wirklich keine Spur mehr von der Seite gibt.
Wichtig ist dabei die Wortwahl „ausblenden“: Die konkrete Seite bleibt im Index, wird aber in den Suchergebnissen nicht mehr ausgespielt. Man muss also nach Nutzung der Option dafür sorgen, dass die entsprechende(n) Seite(n) auch wirklich aus dem Index entfernt werden. Dafür muss man am besten das Robots-Meta-Tag „noindex“ in die jeweilige(n) Seite(n) einbauen.
Das Ausblenden der Seiten funktioniert nur temporär (90 Tage) – überbrückt aber die Zeit, bis die Seite(n) dann wirklich aus dem Index entfernt wurde(n).
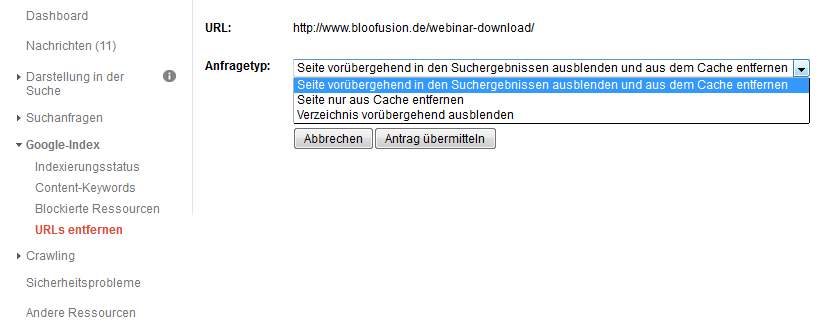
Abbildung 3: Über die Google Search Console können Seiten temporär in den Suchergebnissen ausgeblendet werden.
Crawling-Fehler
In der Rubrik „Crawling-Fehler“ werden recht unterschiedliche Fehler aufgeführt, die Google beim Crawling findet. Denn: Nicht jede Seite, die Google herunterladen möchte, liefert auch immer den gewünschten HTTP-Code 200 („Seite gefunden“). Manchmal findet Google z. B. über fehlerhafte interne oder externe Verlinkungen auch Seiten, die es eben nicht mehr gibt. Typisch ist da vor allem der Fehler 404 („Nicht gefunden“).
Die Google Search Console zeigt aber nicht nur 404-Fehler an, sondern z. B. auch den sogenannten „Soft 404“. Dieser Fehler tritt dann auf, wenn die Website falsch konfiguriert ist und z. B. bei einer nicht mehr existenten URL mit einem HTTP-Code 200 („Gefunden“) statt 404 („Nicht gefunden“) antwortet. Dann sollte man seinen Web-Server so ändern, dass auch der richtige Code ausgeliefert wird.
Grundsätzlich muss man aber sagen, dass diese Fehler von Google angezeigt werden, um daraus zu lernen und die Website zu verbessern. Die oft empfundene Angst, dass eine Vielzahl von 404-Fehlern einer Website schaden kann, ist nicht unbedingt begründet.
Trotzdem sollte man sich an die Fehlerbehebung setzen und prüfen, wie man die einzelnen Probleme lösen kann. Ein Manko hat die Google Search Console aber leider: Man kann zwar bestimmte URLs aus den Fehlerlisten entfernen – diese tauchen aber später immer wieder auf. Es reicht also nicht aus, die Fehler einfach nur „wegzuklicken“. Man muss sie auch wirklich beheben, z. B. durch das Sperren bestimmter Seiten in der robots.txt.
XML-Sitemaps
Das Hinterlegen von XML-Sitemaps ist vor allem bei großen Websites sinnvoll. Wer viele Seiten/Inhalte auf seiner Website hat, kann über die XML-Sitemaps Google mitteilen, welche Seiten wichtig sind. Zudem können an die Seiten noch Zusatzinformationen über die Wichtigkeit und die Änderungshäufigkeit angehängt werden.
Wie gesagt: Wirklich sinnvoll ist das nur bei großen Websites, denn ansonsten schafft es der Crawler auch ohne XML-Sitemap, alle innerhalb der Website verlinkten Informationen zu crawlen. Man darf hier also keine Wunder erwarten.
XML-Sitemaps bieten aber im Zusammenspiel mit der Google Search Console ein interessantes Potenzial. In der Console wird nämlich pro Sitemap angezeigt, wie viele Seiten diese enthält und wie viele dieser URLs sich dann auch wirklich im Index befinden. Wer also seine XML-Sitemaps gut strukturiert und z. B. alle Top-Seller-Produkte in einer eigenen Sitemap aufführt, kann so zielsicher überprüfen, ob diese auch gut indexiert werden.
Ähnlich wie beim Indexierungsstatus enden die Möglichkeiten der Google Search Console dann aber auch wieder: Man kann nicht einsehen, welche Seiten indexiert und welche nicht indexiert werden.
URL-Parameter
URL-Parameter sind Teil der URL. Diese werden per Fragezeichen von der URL und untereinander per Kaufmanns-Und („&“) abgetrennt. Die URL http://www.meinewebsite.de/sale/?source=adwords&list=all enthält also zwei Parameter („source“ und „list“). Über solche URL-Parameter wird dann gesteuert, was auf der Seite dargestellt werden soll.
Solche Parameter sind natürlich nicht schädlich, aber oft die Quelle von Duplicate-Content-Problemen. Häufig werden Tracking-Parameter wie „utm_source“ angehängt, was dann zu unterschiedlichen URLs mit gleichem Inhalt führt.
In der Google Search Console kann man Google daher mehr Informationen über die einzelnen Parameter mitteilen. Vor allem ist es wichtig, Tracking-Parameter – also solche, die den Seiteninhalt nicht verändern – entsprechend zu markieren (siehe Abbildung 4). Dazu wählt man für den jeweiligen Parameter die Option „Nein: Hat keinen Einfluss auf den Seiteninhalt“ aus. Fortan wird sich Google bemühen, diesen Parameter aus URLs zu entfernen, sodass der Crawler solche Dubletten idealerweise gar nicht erst herunterlädt.
Für den Fall, dass ein Parameter den Seiteninhalt doch ändert, kann man übrigens noch weitergehende Informationen festlegen. Hier sollte man einfach die entsprechenden Fragen beantworten, um Google möglichst viele Informationen über die Funktionsweise des jeweiligen Parameters mitzuliefern. So kann man z. B. auswählen, dass ein Parameter wie „sort“ dazu dient, den Seiteninhalt anders zu sortieren.

Abbildung 4: Irrelevante URL-Parameter sollten über die Google Search Console markiert werden.
Abrufen wie durch Google
Die Funktion „Abruf wie durch Google“ kann bei der Diagnose einer bestimmten Seite helfen. Wenn man eine bestimmte URL eingibt und dann auf „Abrufen“ klickt, kann man prüfen, ob die Seite z. B. per robots.txt für Suchmaschinen gesperrt ist oder ob es andere Probleme gibt. So kann es gelegentlich bei internationalen Websites dazu kommen, dass Besucher anhand der IP-Adresse auf die jeweilige Länderversion umgeleitet werden. Das kann sinnvoll sein – aber auch Google greift ja auf die Seite zu und wird dann evtl. auch umgeleitet. Das kann man über die „Abrufen“-Funktion prüfen, denn darüber sieht man, was der „echte“ Googlebot auch sehen würde.
Hilfreich ist aber auch die Funktion „Abrufen und Rendern“. Google analysiert ja nicht mehr einfach nur eine HTML-Seite, sondern lädt alle Bestandteile einer Seite (CSS, JavaScript, Bilder …) herunter, um ein vollständiges Bild einer Seite zu erhalten. Wenn man nun diese Funktion auswählt, sieht man, wie Google die Seite darstellt. Falls man also z. B. Produktbilder für Suchmaschinen gesperrt hat, würde man beim Rendern einer Produktdetailseite an den jeweiligen Stellen weiße Flecken sehen. Im Browser hingegen würde die Seite korrekt dargestellt, da der Browser sich nicht an die robots.txt hält.
Man sollte also die wichtigsten Seitentypen durchprüfen, um solche Fehlerquellen zu finden. Google listet dafür auch alle Ressourcen auf, die für die Suchmaschine gesperrt sind. Man darf durchaus einzelne Elemente für Suchmaschinen sperren (z. B. Tracking-Skripte), aber alle wichtigen Elemente (Bilder, CSS-Dateien, Fonts …) sollten für Google zugänglich sein.
Die „Abrufen“-Funktion hat übrigens noch einen Vorteil: Wenn eine Seite korrekt abgerufen werden konnte, kann man sie direkt in den Index befördern (Klick auf „An den Index senden“). Hier gibt es allerdings Begrenzungen, sodass man diese Funktion nur wohldosiert nutzen sollte.
robots.txt-Tester
Die robots.txt wurde schon mehrfach erwähnt. Sie dient dazu, das Crawling zu beschränken, also zu verhindern, dass bestimmte Seiten vom Crawler geladen werden. Wer bestimmte Inhalte zukünftig sperren und einfach nur prüfen möchte, ob bestimmte URLs vom Crawler geladen werden können oder nicht, kann dazu den robots.txt-Tester verwenden.
Mit dem Tool kann man die bestehende robots.txt herunterladen und diese auch bearbeiten. Man kann also Google eine bestimmte robots.txt „vorgaukeln“ und dann prüfen, wie sich diese auf bestimmte Seiten auswirkt. So kann man eine URL eingeben und dann ermitteln, ob die Seite gesperrt ist. Wie in Abbildung 5 zu sehen ist, stellt Google dann auch dar, welche Regel der robots.txt jeweils greift.
Der Tester prüft aber immer nur einzelne URLs ab. Man könnte also die robots.txt und damit tausende indexierte Seiten sperren, ohne dass man es merken würde. Deswegen sollte man mit Änderungen immer sehr vorsichtig sein und diese nur vornehmen, wenn man die Auswirkungen auch wirklich abschätzen kann.

Abbildung 5: Der robots.txt-Tester hilft dabei, die Wirksamkeit der Datei robots.txt zu prüfen.
Crawling-Statistiken
Die Crawling-Statistiken in der Google Search Console bieten leider nur relativ übersichtliche Daten. So wird gezeigt, wie viele Seiten pro Tag gecrawlt werden, wie viele Kilobyte heruntergeladen werden und wie lange das Laden einer Seite durchschnittlich gedauert hat.
Einstellungsmöglichkeiten gibt es hier nicht, sodass man eigentlich nur prüfen kann, ob es relevante Änderungen gibt – vor allem bei der Ladezeit einer Seite. Wichtig ist hier, dass es nur um die reine Ladezeit einer HTML-Seite geht. In anderen Tools – vor allem in Google Analytics – werden zwar auch Ladezeiten angezeigt, aber diese beziehen sich dann in der Regel auf die gesamte Seite (also inkl. CSS, Bilder …). Auch kann man in der Google Search Console leider nicht abrufen, welche Seiten besonders lange brauchen. Die Aussagekraft der Daten ist also wirklich recht beschränkt.
Fazit
Wenn man die Einschränkungen der jeweiligen Funktionen beachtet, kann man die Google Search Console sehr gut nutzen, um bestmöglichen Einfluss auf Crawling und Indexierung zu nehmen. Besonders wichtig für die meisten Website-Betreiber sind wohl die Funktionen „URL-Parameter“, „XML-Sitemaps“ und „Abrufen wie durch Google“, um einerseits Probleme zu finden und andererseits möglichst viele Seiten in den Index zu befördern.
Übrigens: Dieser Artikel stammt aus der Ausgabe 63 unseres Magazins suchradar. Falls Sie die Ausgabe noch nicht kennen, können Sie diese und alle früheren Ausgaben im suchradar-Archiv kostenlos herunterladen.

Markus Hövener
Markus Hövener ist Gründer und SEO Advocate der auf SEO und SEA spezialisierten Online-Marketing-Agentur Bloofusion. Als geschäftsführender Gesellschafter von Bloofusion Germany ist er verantwortlich für alle Aktivitäten in Deutschland, Österreich und der Schweiz. Markus Hövener ist Buchautor, Podcaster und Autor vieler Artikel und Studien rund um SEO.
Markus hat vier Kinder, spielt in seiner Freizeit gerne Klavier (vor allem Jazz) und genießt das Leben.
Neueste Artikel von Markus Hövener (alle ansehen)
- Welche SEO-Konferenz ist die beste? [Search Camp 317] - 23. April 2024
- SEO-Trainee-Programme: Ganz einfach SEOs ausbilden? [Search Camp 316] - 16. April 2024
- SEO-Monatsrückblick März 2024: Google Updates, Search Console + mehr [Search Camp 315] - 2. April 2024
- Recap zur SMX München: Die wichtigsten Take-Aways [Search Camp 314] - 19. März 2024
- Sichtbarkeit und/oder Traffic gehen nach unten: Woran kann’s liegen? [Search Camp 313] - 12. März 2024

April 22nd, 2017 at 21:41
Hallo Markus,
danke für diese ausführlichen Artikel. Ich beobachte bei mir in der Google Search Console schon längere Zeit, dass ich 22 Bilder eingereicht habe jedoch nur 1 Stück indiziert wird. Alle Bilder (Dateinamen) sind sprechend benannt und auch die Alt und Title Texte sind entsprechend befüllt. Hast du eine Idee warum nur 1 Bild indiziert wird? Seite ist http://www.wohnmobil-mieten-billig.de
April 25th, 2017 at 10:48
Ohne die XML-Sitemap zu sehen, kann ich dazu natürlich nichts sagen… ABER: Die Indexierungsraten bei Bildern sind oftmals deutlich schlechter als bei HTML-Inhalten… so verwunderlich finde ich das also nicht unbedingt…